
今回は、雑談をする為の会話ロボットを作って行きます。
楽しそうなら作ってみて♪
この記事では以下が学べます。
- ボタン制御
- マイク入力
- スピーカー出力
- Python
- WebAPI
- 音声認識
- 音声合成
やりたいこと
・話者がボタンを押している間に喋った内容を取得し、
・喋った内容に対する応答内容を生成し、
・応答内容をスピーカーから喋らせる。
システム構成図
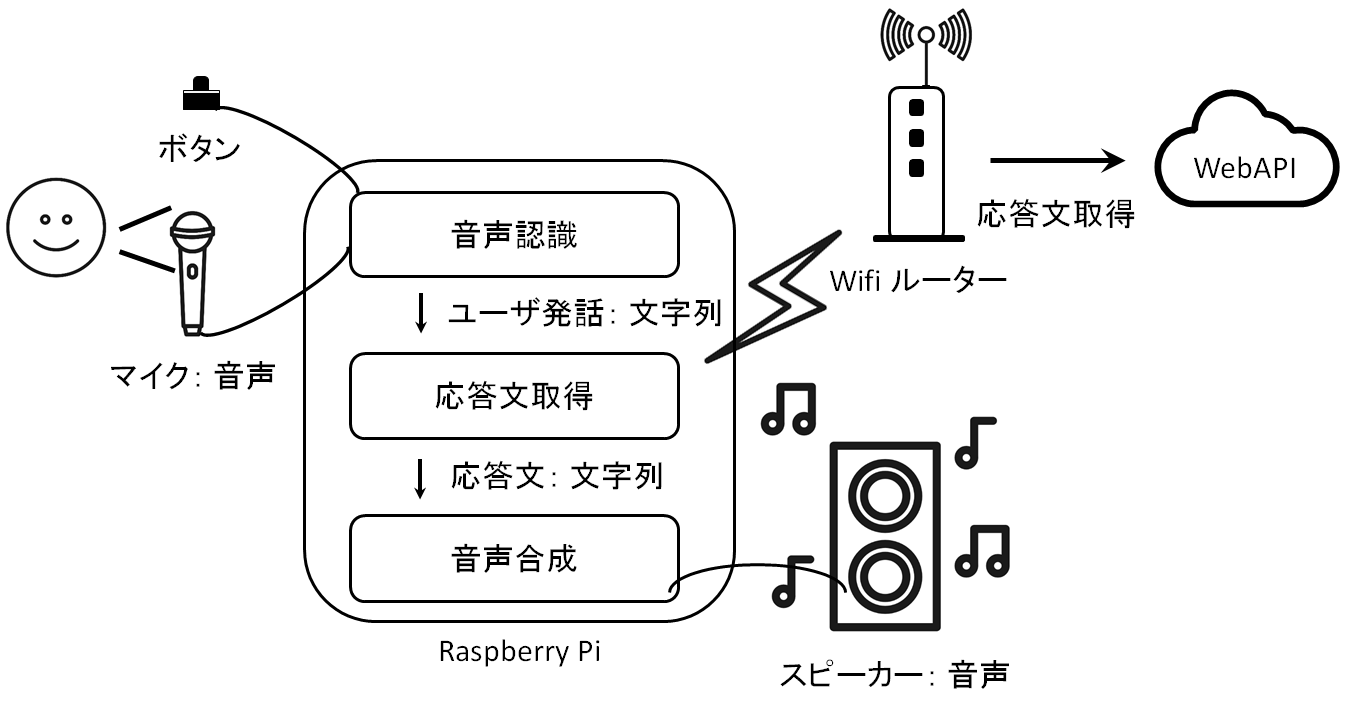
やることリスト
上記の「やりたいこと」をみて、
どんな作業が必要か、自分で項目を考えてみてください。
これを考えることで、「プログラミング的思考」が身に付いていきます。
| 番号 | 作業項目 | 備考 |
| 1 | やりたいこと・システム構成図の作成 | |
| 2 | やることリストの作成 | 作業項目の洗い出し |
| 3 | 部品の準備 | |
| 4 | ボタンが押されたことを判断する | |
| 5 | マイクに喋った内容を音声ファイルに保存 | |
| 6 | マイクに喋った内容を文字列に変換 | 音声認識 |
| 7 | 応答内容(文字列)の取得 | WebAPI |
| 8 | 文字列を音声に変換し、スピーカーから音声出力 | 音声合成 |
| 9 | 以上の機能をまとめて、 やりたいことを実現する! |
部品の準備
今回のシステムに必要な部品です。
不足している部品があれば購入下さい。
| 部品名 | 備考 |
| Raspberry Pi | 別途、電源・SDカード・HDMIケーブルが必要です。 |
| ブレッドボード(※1) | |
| ジャンパー線(※1) | オスーメス:2本 |
| ボタン(※1) | タクトスイッチ:1個 |
| スピーカー | ダイソーのUSBミニスピーカー(300円)がお薦めです。 |
| マイク | 「超小型 USBミニマイク」が値段的にお薦めです。 |
購入に必要な部品を、
Raspberry Pi 関連に記載しています。
※1)「電子工作キット」内に全て含まれています。
ラズパイは、電源を入れただけでは起動しません。
ラズパイの起動手順の記事を参照ください。

ボタンが押されたことを判断する
以下記事に、回路・配線図・プログラムの情報を書いていまので、
参照下さい。
マイクに喋った内容を音声ファイルに保存
マイクをラズパイに接続してください。
pyaudioライブラリのインストール
pythonで、オーディオデバイスを操作する為に、
以下コマンドを用いてpyaudioライブラリをインストールします。
sudo apt-get install python3-pyaudioマイクのデバイス番号取得
サウンドレコーダーデバイスのリストを取得する為に、
arecord -l
コマンドを実行します。
以下出力結果の通り、
カード 2: Commu・・・・
と表示されていますので、
以下プログラム中の
CARD_NUM = *
に、2 を入れてあげます。
ご自身の環境に合わせて変更ください。
pi@raspberrypi:~/work/bot $ arecord -l **** ハードウェアデバイス CAPTURE のリスト **** カード 2: Communicator [Polycom Communicator], デバイス 0: USB Audio [USB Audio] サブデバイス: 1/1 サブデバイス #0: subdevice #0
プログラム
以下ディレクトリ通り、ディレクトリとファイルを作成する。
この章では、以下赤字のファイルを修正する。
/home/pi/work/weather/
└record.py
record.py
import pyaudio
import time
import wave
CHUNK = 4096
CHANNELS = 1 # モノラル
FRAME_RATE = 48000
# カード番号
CARD_NUM = 2
class Audio:
wav_file = None
stream = None
def __init__(self):
self.audio = pyaudio.PyAudio()
for x in range(0, self.audio.get_device_count()):
print(self.audio.get_device_info_by_index(x))
# コールバック関数
def callback(self, in_data, frame_count, time_info, status):
# wavに保存する
self.wav_file.writeframes(in_data)
return None, pyaudio.paContinue
# 録音開始
def start_record(self):
# wavファイルを開く
self.wav_file = wave.open('record.wav', 'w')
self.wav_file.setnchannels(CHANNELS)
self.wav_file.setsampwidth(2) # 16bits
self.wav_file.setframerate(FRAME_RATE)
# ストリームを開始
self.stream = self.audio.open(format=self.audio.get_format_from_width(self.wav_file.getsampwidth()),
channels=self.wav_file.getnchannels(),
rate=self.wav_file.getframerate(),
input_device_index=CARD_NUM,
input=True,
output=False,
frames_per_buffer=CHUNK,
stream_callback=self.callback)
# 録音停止
def stop_record(self):
# ストリームを止める
self.stream.stop_stream()
self.stream.close()
# wavファイルを閉じる
self.wav_file.close()
# インスタンスの破棄
def destructor(self):
# pyaudioインスタンスを破棄する
self.audio.terminate()
if __name__ == '__main__':
audio = Audio()
audio.start_record()
time.sleep(5) # 5秒間待つ
audio.stop_record()
audio.destructor()
実行
コマンドラインから、先程作成した record.py のディレクトリに移動し、
以下コマンドでプログラムを実行する。
本プログラムでは、5秒間マイクからの音声を録音するようにしています。
5秒間マイクに向かって何か喋ってみてください。
python3 record.py5秒間経った後に、
record.py がある同じディレクトリに、
record.wav ファイルが出来ていると思いますので、
ファイルを実行してみてください。
先程喋った内容が再生されれば成功です!
音声を再生する際の注意点として、
ラズパイ自体には音を再生するデバイスが無いので、
ラズパイに、HDMIケーブルでテレビと接続するか、
スピーカーを接続してください。
参考
■PyAudio Documentation
https://people.csail.mit.edu/hubert/pyaudio/docs/
マイクに喋った内容を文字列に変換
今回は、マイクに喋った内容を文字列に変換するサービス、つまり、音声認識として、
GCP(Google Cloud Platform)の、Cloud Speech-to-Text API を使っていきます。
他にも、音声認識としてはフリーの Julius が存在しますが、
音声認識の精度が悪いそうということで、Cloud Speech-to-Textを使用します。
もし、特定の言葉を認識させる コマンド用途 であれば、
音声認識の精度を上げる為に独自の辞書を作れば、Juliusもいいかもですね。
Cloud Speech-to-Text API を試してみる
Cloud Speech-to-Text API の精度が知りたい方は、
音声認識のお試しが出来ます。
以下、Cloud Speech-to-Text のURLへ行き、
ブラウザ上で、喋った内容が表示されます。
https://cloud.google.com/speech-to-text?hl=ja
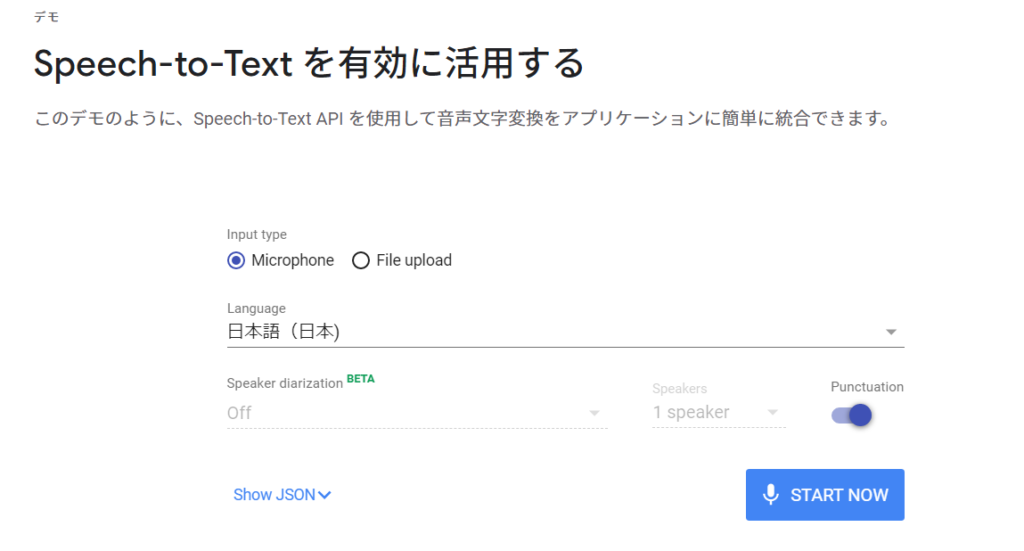
Cloud Speech-to-Text APIを使うには
Cloud Speech-to-Text APIを使うには、
GCP(Google Cloud Platform)側の設定が必要となります。
GCP(Google Cloud Platform)の設定
Google Cloud Platform の「無料トライアル」
Google Cloud Platform には、「無料トライアル」があります。
無料トライアルの内容は、
・90日間、$300 分のクレジットが利用可能
・無料トライアル期間が終了しても、自動的に請求されることはない
とのことなので安心ですね。
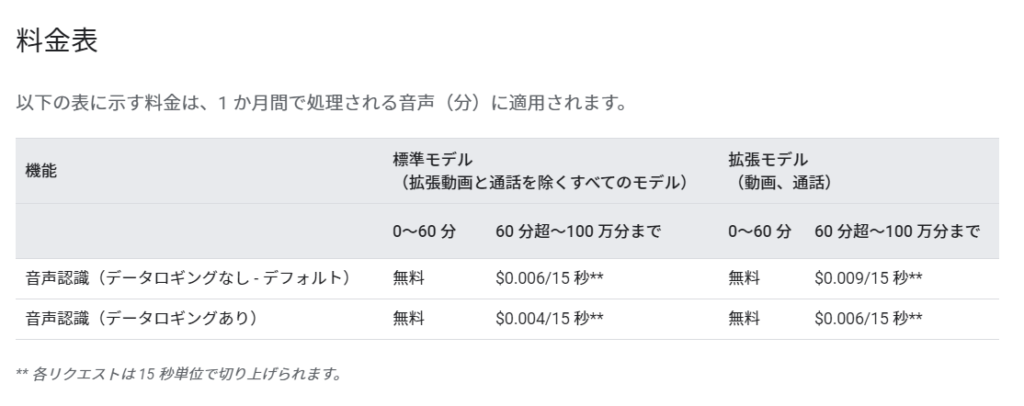
以下が、Speech-to-Text の料金表になります。
$300 って、何秒喋れるんだ・・・?
https://cloud.google.com/speech-to-text/pricing?hl=ja
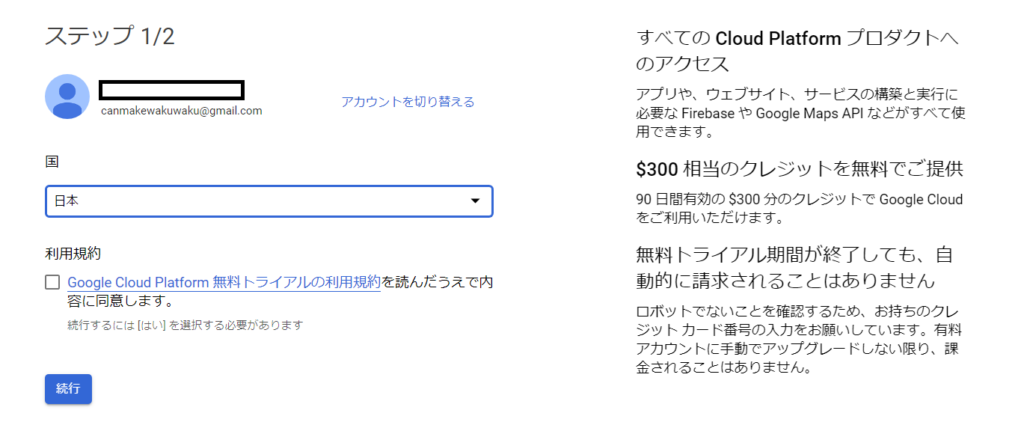
Google Cloud Platform への登録
以下、Google Cloud Platform のサイトへ行き、
「無料トライアル」から登録を行います。
https://cloud.google.com/
「国」、「利用規約」を設定後、
「続行」ボタンを押します。
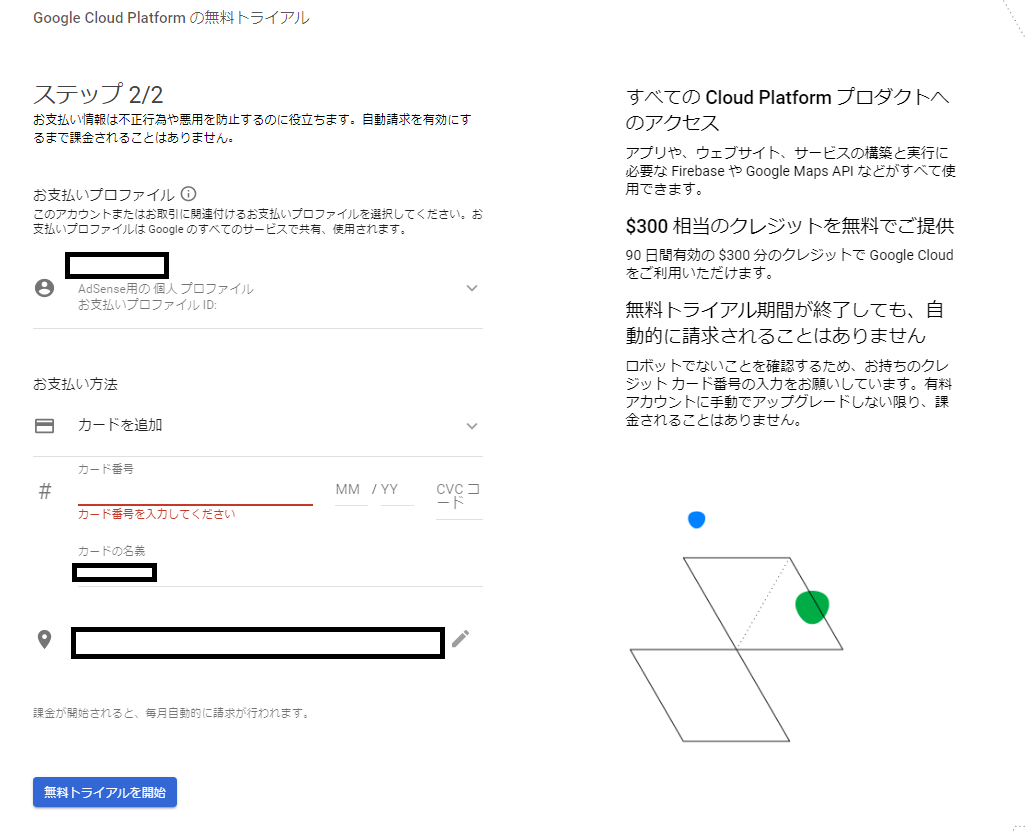
「カード番号」、「カードの名義」、「住所」を入力し、
「無料トライアルを開始」ボタンを押します。
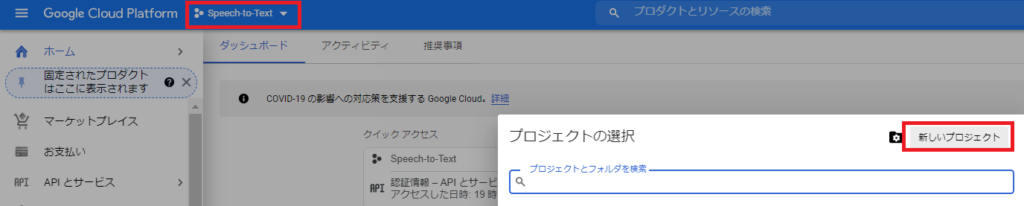
プロジェクトの作成
下図の赤枠「Speech-to-Text」→「新しいプロジェクト」を押して、
プロジェクト名を記載します。
私は “Speech-to-Text” にしました。
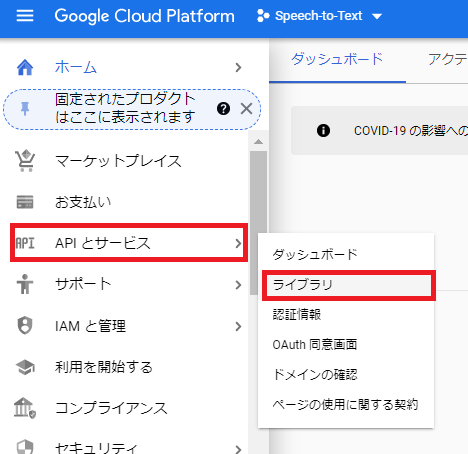
Cloud Speech-to-Text API の有効化
下図の赤枠「APIとサービス」→「ライブラリ」を押します。
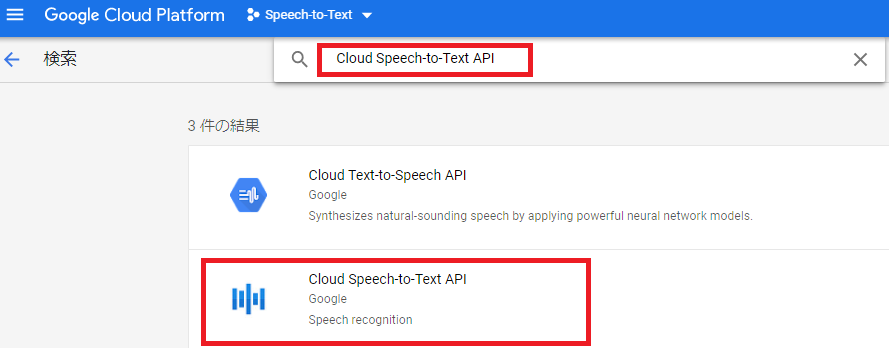
下図の赤枠に「Cloud Speech-to-Text API」を入力し、
下の「Cloud Speech-to-Text API」を選択し、「有効にする」ボタンを押す。
認証情報の作成
以下、Google Cloud Platform のサイトへ行き、
「サービス アカウントの作成」、「環境変数を設定する」を実施ください。
https://cloud.google.com/docs/authentication/getting-started#auth-cloud-implicit-python
上記で実施した、
サービス アカウント キーが含まれる JSON ファイルのファイルパスをメモして下さい。
プログラムで使用します。
プログラム
以下ディレクトリ通り、ディレクトリとファイルを作成する。
この章では、以下赤字のファイルを修正する。
/home/pi/work/bot/
└speech2text.py
クライアント ライブラリのインストール
pip3 install --upgrade google-cloud-speech嵌った点:
pip install ・・・
でインストールすると、
Running setup.py bdist_wheel for grpcio
の処理から進まず、インストールが終わりませんでした。
そこで、pip3 install ・・・ にすると無事インストール出来ました。
speech2text.py
# -*- coding: utf-8 -*-
import io
import os
from google.cloud import speech
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/home/pi/Downloads/my-key.json'
# クライアントの生成
client = speech.SpeechClient()
# 音声ファイル名の生成
file_name = os.path.join(os.path.dirname(__file__), "record.wav")
print('file_name=' + file_name)
def speech2text():
# 音声ファイルの読み込み
with io.open(file_name, "rb") as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content)
# 音声ファイルをテキストに変換
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=48000,
language_code="ja-JP",
)
return client.recognize(config=config, audio=audio)
if __name__ == '__main__':
res = speech2text()
# 出力
for result in res.results:
print("Transcript: {}".format(result.alternatives[0].transcript))
実行
コマンドラインから、先程作成した speech2text.py があるディレクトリに移動する。
音声ファイルの作成
事前に、ラズパイにマイクを接続しておいてください。
■arecord -l にて、録音デバイスを確認する。
pi@raspberrypi:~/work/bot $ arecord -l **** ハードウェアデバイス CAPTURE のリスト **** カード 2: Communicator [Polycom Communicator], デバイス 0: USB Audio [USB Audio] サブデバイス: 1/1 サブデバイス #0: subdevice #0
上記より、カード番号は”2”、デバイス番号は”0”だと分かります。
■録音する
以下コマンドを実行し、
マイクに向かって好きな言葉を話してください。
話し終ったら、「Ctrl + C」で終了させて下さい。
arecord -f S16_LE -r 48000 -D plughw:2,0 test.wav喋った内容を文字列に変換
以下コマンドでプログラムを実行する。
python3 speech2text.py結果として、以下のような表示が出てきます。
pi@raspberrypi:~/work/bot $ python3 speech2text.py file_name=test.wav Transcript: おはようございます今日の天気は晴れです
参考
Speech-to-Text API の Cloud クライアント ライブラリの利用方法が、
以下URLに記載されています。
https://cloud.google.com/speech-to-text/docs/libraries?hl=ja#client-libraries-usage-python
応答内容(文字列)の取得
話しかけた内容に対して、雑談を返してくれるサービスとして、
Chaplus(Chat + Plusの造語) のWebAPI を使用します。
Chaplus APIは、チャットボットを始めとする『対話型』サービスに、
雑談機能やQ&A自動応答機能を手軽に実装することができるAPIです。
本APIは無料で使用出来ます。
API keyの取得
Chaplus APIを使用する為には、API key を取得する必要があります。
API keyとは、APIを利用する為の認可証だと思ってください。
API keyを取得するには、
以下ChaplusのURLにアクセスします。
https://www.chaplus.jp/
画面最下部の「メールアドレス」と「利用目的」を入力し、
「利用規約に同意して登録」ボタンを押すと、
メールアドレスにAPI keyが送られてきます。
※注意点:
「お使いのメールアプリによっては、
迷惑メールにメールが振り分けてしまっている可能性がございます。」
とのことです。
私は迷惑メールに入っていました。。。
プログラム
以下ディレクトリ通り、ディレクトリとファイルを作成する。
この章では、以下赤字のファイルを修正する。
/home/pi/work/bot/
└chat_bot.py
chat_bot.py
以下プログラム内の、
CHAPLUS_APIKEY = ”
に、上記で取得したAPI keyを入力してください。
import requests
import json
CHAPLUS_APIKEY = '{あなたがCHAPLUSから取得したAPIKEY}'
def chaplus_post(utterance: dict):
url = f'https://www.chaplus.jp/v1/chat?apikey={CHAPLUS_APIKEY}'
headers = {
'Content-Type': 'application/json'
}
response = requests.post(url=url, headers=headers, data=json.dumps(utterance))
data = None
if response.status_code == requests.codes.ok:
text = response.text
data = json.loads(text)
print(json.dumps(data, indent=2, ensure_ascii=False))
return data
if __name__ == '__main__':
utterance = {
# 発話内容
'utterance': '元気?',
# 話者(こちら)の名前
'username': 'ししまる',
# 応答者(WebAPI側)情報
'agentState': {
'agentName': 'エージェント',
'age': '20',
'tone': 'kansai '
},
# 追加情報
'addition': {
'utterancePairs': [
{
'utterance': '元気ですか?',
'response': 'バッチグーだよ',
'options': ''
}
]
}
}
chaplus_post(utterance)
実行
コマンドラインから、先程作成した chat_bot.py のディレクトリに移動し、
以下コマンドでプログラムを実行する。
python3 chat_bot.py
結果として、以下のような値(抜粋しています)が表示されます。
つまり、上記プログラム中の’utterance’: ‘元気?’
という言葉をChaplus APIに送ると、
“utterance”: “すこぶってます\n”が返ってきます。
# responsesの中で、最もscore値が高かった応答が、bestResponseに入っていきます。
上記プログラム中の’utterance’: ‘***’
に好きな言葉を入れて、どんな応答が返ってくるのか、
楽しんでみてください♪
{
"bestResponse": {
"utterance": "すこぶってます\n",
"score": 0.7629,
"url": "",
"options": null
},
"responses": [
{
"utterance": "すこぶってます\n",
"score": 0.7629,
"url": "",
"options": null
},
{
"utterance": "圧倒的絶好調\n",
"score": 0.5629,
"url": "",
"options": null
},
}
参考
chaplus APIは、自分なりの応答、NGワードを設定出来たり、
キャラクターの変更も出来ます。
以下API仕様を確認して、色々試してみてください♪
chaplus 雑談応答API 仕様

chaplus Q&A応答API 仕様

文字列を音声に変換し、スピーカーから音声出力
以下記事を参照ください。

まとめ
まとめです。
これまで作成した上記機能を組み合わせて、
ボタンを押して、【会話ロボット】作って行きます。
プログラム
この章では、以下赤字のファイルを修正します。
それ以外は、上記ファイルのままで使用します。
/home/pi/work/weather/
├app.py・・・main処理
├record.py・・・マイクに喋った内容を音声ファイルに保存
├speech2text.py・・・音声ファイルをテキスト変換(音声認識)
├chat_bot.py・・・応答(雑談)内容の取得
└talk.py・・・文字列を音声に変換し、スピーカーから音声出力
app.py
# -*- coding: utf-8 -*-
from speech2text import speech2text
import RPi.GPIO as GPIO
import time
import sys
import record
import chat_bot
import talk
# LED_GPIO 変数に 24をセット
SW_GPIO = 24
# GPIO.BCMを設定することで、GPIO番号で制御出来るようになります。
GPIO.setmode(GPIO.BCM)
# GPIO.INを設定することで、入力モードになります。
# pull_up_down=GPIO.PUD_DOWNにすることで、内部プルダウンになります。
GPIO.setup(SW_GPIO, GPIO.IN, pull_up_down=GPIO.PUD_DOWN)
UTTERANCE = {
# 発話内容
'utterance': '元気?',
# 話者(こちら)の名前
'username': 'ししまる',
# 応答者(WebAPI側)情報
'agentState': {
'agentName': 'エージェント',
'age': '20',
'tone': 'kansai '
},
}
if __name__ == '__main__':
# Audioインスタンスの作成
audio = record.Audio()
while True:
try:
# ボタン押し
if GPIO.input(SW_GPIO) == 1:
# マイクに喋った内容を音声ファイルに保存
print('start record')
audio.start_record()
while GPIO.input(SW_GPIO) == 1:
time.sleep(1) # 1秒間待つ
audio.stop_record()
print('stop record')
# 音声ファイルをテキスト変換
text = speech2text()
# 出力
utterance = ''
for result in text.results:
print("Transcript: {}".format(result.alternatives[0].transcript))
utterance = result.alternatives[0].transcript
break
# 応答(雑談)内容の取得
chat = None
if utterance:
UTTERANCE['utterance'] = utterance
res = chat_bot.chaplus_post(UTTERANCE)
chat = res.get('bestResponse').get('utterance')
# 文字列を音声に変換し、スピーカーから音声出力
if chat:
talk.talk(chat)
time.sleep(1) # 0.5秒間待つ
# Ctrl+Cキーを押すと処理を停止
except KeyboardInterrupt:
audio.stop_record()
# ピンの設定を初期化
# この処理をしないと、次回 プログラムを実行した時に「ピンが使用中」のエラーになります。
GPIO.cleanup()
sys.exit()
実行
コマンドラインから、先程作成した app.py のディレクトリに移動し、
以下コマンドでプログラムを実行する。
本プログラムでは、ボタンを押している間に喋った内容を録音します。
逆に、ボタンを離しているに喋っている内容は録音されません。
録音した内容に応じて、会話ロボットが雑談を返してくれます♪
色んな会話を楽しんでみてください♪
python3 app.py最後に
如何だったでしょうか?
ボタンを押したか判断出来た時、
マイクに喋った内容が文字列に変換出来た時、
雑談が出来た時、
ワクワクしましたよね♪
今回の会話ロボットは、
会話が成り立つことが多くてめっちゃ楽しいです!!!
今後も、Raspberry Pi と Python を使ってワクワクするモノを作って行きます。
楽しみにしていてくださいね。
不明な点があればページTOPの「お問い合わせ」にてご連絡下さい。

